
4. Juli 2019 von Thomas Mayr
Fundierte Auswahl eines Frameworks – oder das haben wir immer schon so gemacht (Teil 1)
Steht ihr in einem Projekt vor der Frage, welches Framework für einen bestimmten Zweck eingesetzt werden soll, wird die Entscheidung oft nach persönlichen Vorlieben einzelner Projektmitglieder oder des Architekten getroffen. Auch die Team-Erfahrungen mit einem bestimmten Framework stellen häufig ein entscheidendes Auswahlkriterium dar, das gerade bei komplexen Frameworks wie Hibernate oder JPA den Erfolg oder Misserfolg maßgeblich beeinflussen kann.
Spätestens dann, wenn ihr euch im Projektteam nicht einigen könnt, solltet ihr eine Auswahl treffen, die auf festzulegenden Entscheidungskriterien basiert. Oft passt nicht jedes Framework zur Art der Anwendung. So erfordern interaktive Anwendungen, Serviceanwendungen und Batch-Prozesse unter Umständen eine andere Art von Framework als die, die ihr vielleicht aus euren vorherigen Projekten kennt. Außerdem bleibt die Zeit in der IT erfahrungsgemäß nicht stehen. So werden neue Frameworks angeboten oder im Java-Bereich wird die Standardbibliothek erweitert, was die bisher verwendeten Frameworks überflüssig macht.
Wenn ihr in eurem Projekt also die Chance habt, ein Framework auszuwählen, solltet ihr diese nutzen und versuchen, alte Gewohnheiten über Bord zu werfen.
In meinem Blog-Beitrag möchte ich drei Java Frameworks zur Implementierung einer Persistenzschicht nach den weitgehend objektiven Kriterien „Aufwand“ und „Performanz“ vergleichen. Folgende Varianten werden gegenübergestellt:
1. Standard-JDBC
2. Klassisches Hibernate
3. JPA/Hibernate
Im ersten Teil vergleiche ich zunächst den Aufwand der Implementierung, ziehe ein konkretes Beispiel zur Erklärung heran und gehe auf Standard JDBC ein.
Implementierungsaufwand
Ein Vergleich kann erst erfolgen, wenn wir uns alle Varianten - Standard-JDBC, klassisches Hibernate und JPA/Hibernate - nacheinander angesehen haben. Im Vorfeld möchte ich euch aber mein Konzept vorstellen, um den Implementierungsaufwand zu messen. Dazu habe ich die Anzahl von Klassen, Methoden und Codezeilen pro Geschäftsklasse und Attribut ermittelt. Je nach definiertem Entwicklungsprozess bedeutet das Erstellen eines dieser Artefakte nicht nur das Programmieren der Klasse, Methode oder Zeile, auch das Design, die Dokumentation, das Review und Testing spielen eine Rolle. Übrigens: Falls ihr in eurem Projekt Heuristiken gesammelt habt, könnt ihr aus diesen Zahlen leicht eine Kostenschätzung für eine weitere Geschäftsklasse oder eine Menge von neuen Attributen berechnen.
Ich habe jede Anweisung bis zum Strichpunkt und jeden zusätzlichen Methodenaufruf als eine Anweisung gezählt. Die folgende Zeile zählt daher beispielsweise als zwei Anweisungen:
x.set(y.get());
Jedes if/else, try/catch/finally, jede Schleife, jede Annotation und jedes XML-Element habe ich jeweils als eine Anweisung gezählt.
Den Initialisierungsaufwand und den Aufwand für die Transaktionssteuerung der verschiedenen Implementierungen habe ich an dieser Stelle nicht betrachtet, da er bei allen Varianten sehr ähnlich ist und nur einmalig anfällt.
Der Implementierungsaufwand und die Kosten sind in der Regel entscheidende Kriterien für den Kunden oder für die Projektleitung.
Die Effizienz eines Projektteams bemisst sich in der Regel nach der Formel „Wert einer Funktionalität / Kosten“ oder anders ausgedrückt „Funktionalität / Anzahl Programmzeilen“. Dementsprechend erzielt ihr die beste Effizienz, wenn ihr eine bestimmte Funktionalität mit Null Zeilen Code liefern könnt. Die Effizienz geht in diesem Fall dann gegen unendlich.
Ich habe aber auch schon IT-Leiter erlebt, die die Leistung von Programmierern nach Codezeilen pro Stunde messen. In diesem Fall ist der so berechnete Aufwand natürlich kein Entscheidungskriterium. Die Devise muss an dieser Stelle lauten: soviel unsinnigen Code wie möglich in kurzer Zeit implementieren.
Ein Fallbeispiel
Gehen wir von folgendem Beispiel aus: Es liegt eine Geschäftsklassenhierarchie vor, die in einer Datenbank gespeichert wird und aus der gelesen werden soll. Die Geschäftsklassen sind dabei technologiefreie Java-Klassen. Diese haben einen Konstruktor, der alle Attribute initialisiert und sie verfügen über Methoden, die diese Attributwerte zurückliefern. Außerdem implementieren alle Klassen die Methoden equals() und hashCode(), die auf fachlich eindeutigen Merkmalen basieren. Weiterhin hat jede Geschäftsklasse einen technischen Schlüssel, der von der Datenbank über eine Sequenz generiert wird. In unserem Beispiel wird dazu übrigens Oracle verwendet.
Für die Definition der Funktionalität habe ich folgende Schnittstelle definiert, die dann von den verschiedenen Varianten implementiert wird:
public interface PersistenceFacadeInterface {
<BusinessClass> get<BusinessClass>ById(Long businessObjectId) throws PersistenceException;
void save<BusinessClass>(<BusinessClass> businessObject) throws PersistenceException;
}
Dabei speichert die Methode save<BusinessClass>() die Geschäftsklasse mit all ihren referenzierten Objekten in der Datenbank ab. Falls die Objekte nicht in der Datenbank existieren, werden sie eingefügt und andernfalls aktualisiert. Die Prüfung der Existenz basiert auf dem eindeutig fachlichen und nicht auf dem technischen Schlüssel, da dieser beim Aufruf der Methode nicht bekannt sein muss.
Die Methode get<BusinessClass>ById() liefert das Geschäftsobjekt für den übergebenen technischen Schlüssel mit allen referenzierten Objekten aus der Datenbank zurück.
JDBC-Implementierung
Kommen wir zur ersten Implementierungsvariante – der JDBC-Implementierung. Bei dieser benötigt ihr zunächst eine Methode, um den technischen Schlüssel für ein Geschäftsobjekt aus der Datenbank über die Sequenz zu ermitteln. Diese Methode wird einmal pro Persistenzimplementierung benötigt:
private long getSequenceKey(String sequence) throws PersistenceException {
PreparedStatement statement = null;
ResultSet resultSet = null;
String sqlStatement = "SELECT " + sequence + ".NEXTVAL FROM DUAL";
try {
statement = connection.prepareStatement(sqlStatement,
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
resultSet = statement.executeQuery();
if(!resultSet.next()) {
throw new SQLException("No key returned for sequence " + sequence);
}
return resultSet.getLong("NEXTVAL");
} catch (SQLException exception) {
throw new PersistenceException(exception);
} finally {
closeResultSetAndStatement(resultSet, statement);
}
}
In dem gezeigten Beispiel habe ich eine Hilfsmethode implementiert, die das PreparedStatement und den ResultSet schließt:
private void closeResultSetAndStatement(ResultSet resultSet,
PreparedStatement statement) throws PersistenceException {
try {
if (resultSet != null){
resultSet.close ();
}
} catch (SQLException exception) {
throw new PersistenceException(exception);
} finally {
try {
if (statement != null) {
statement.close ();
}
} catch (SQLException exc) {
//Ignore the statement close exception
}
}
}
Für das Speichern von Geschäftsobjekten werden aktualisierbare Ergebnismengen (ResultSet) verwendet. Das hat den Vorteil, dass ihr nur SQL-SELECT-Anweisungen programmieren müsst und der JDBC-Treiber die Speicherung in einer für die Datenbank optimierten Weise durchführt. Die Methode zum Speichern eines Geschäftsobjekts sieht dann so aus:
public void save<BusinessClass>(<BusinessClass> businessObject) throws PersistenceException {
PreparedStatement statement = null;
ResultSet resultSet = null;
Long key = null;
try {
statement = connection.prepareStatement(SELECT_<BusinessClass>_BY_NUMBER,
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_UPDATABLE);
statement.set<Type>(1, businessObject.get<UniqueKey-1>());
statement.set<Type>(2, businessObject.get<UniqueKey-2>());
resultSet = statement.executeQuery();
resultSet.beforeFirst();
if(!resultSet.next()) {
key = getSequenceKey (SEQUENCE_NAME_<BusinessClass>);
resultSet.moveToInsertRow();
resultSet.updateLong(COLUMN_<BusinessClassID>, key);
businessObject.setId(key);
} else {
businessObject.setId(resultSet.getLong(COLUMN_<BusinessClassID>));
}
resultSet.update<Type>(COLUMN_<Attribute-1>, businessObject.get<Attribute-1>());
…
if(key != null) {
resultSet.insertRow();
} else {
resultSet.updateRow();
}
} catch(SQLException sqlException) {
throw new PersistenceException(sqlException);
} finally {
closeResultSetAndStatement(resultSet, statement);
}
}
Die Anzahl der set()-Aufrufe zum Setzen der Parameter des Prepared Statements hängt natürlich von der Anzahl der Datenbankspalten des fachlichen Schlüssels ab. Ich habe bei der Zählung angenommen, dass dafür durchschnittlich zwei Spalten vorhanden sind - in der Regel eine Fremdschlüsselbeziehung zum Eltern-Objekt und ein Schlüssel zur Identifikation des Kind-Objekts. Egal, ob das Geschäftsobjekt bereits in der Datenbank existiert oder nicht, ich setze den technischen Schlüssel im Geschäftsobjekt (setId()) ein. Dieses Objekt könntet ihr eventuell zur Optimierung verwenden, wenn ihr dasselbe Geschäftsobjekt ändert und nochmal abspeichert. Pro Attribut wird der Wert in der Ergebnismenge mit den zwei Methodenaufrufen resultSet.update<Type>( <ColumnName> und businessObject.get<Attribute>()) gesetzt.
Falls das Geschäftsobjekt Beziehungen zu anderen Objekten hat, die auch gespeichert werden sollen, kommen pro 1..0/1-Beziehung folgende Zeilen hinzu:
<BusinessClass> referencedObject = businessObject.get<BusinessClass>();
if (referencedObject!= null) {
save<BusinessClass>(referencedObject);
}
Für eine 1..n-Beziehung werden dann diese Zeilen ergänzt:
for (<BusinessClass referencedObject : businessObject.get<BusinessClass>Collection()) {
save<BusinessClass>( referencedObject);
}
Zur Ermittlung des Geschäftsobjekts aus der Datenbank sieht die Implementierung so aus:
public <BusinessClass> get<BusinessClass>ById(Long id) throws PersistenceException {
<BusinessClass> businessObject = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
…
try {
statement = connection.prepareStatement(SELECT_<BusinessClass>_BY_ID,
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
statement.setLong(1, Id);
resultSet = statement.executeQuery();
if(resultSet.next()) {
businessObject = new <BusinessClass>(resultSet.get<Type>(COLUMN_<Attribute-1>),
…);
}
return businessObject;
} catch (SQLException sqlException) {
throw new PersistenceException(sqlException);
} finally {
closeResultSetAndStatement(resultSet, statement);
}
}
Um eine 1..0/1-Beziehung zu lesen, wird vor dem Konstruktoraufruf noch folgende Zeile hinzugefügt:
<BusinessClass> referencedObject = get<BusinessClass>ById(resultSet.getLong(COLUMN_<ObjectId>)
Für das Lesen der Objekte einer 1..n-Beziehung wird die nachfolgende Code-Sequenz benötigt. Hier habe ich vorausgesetzt, dass eine Methode zum Hinzufügen von Kind-Objekten zum Geschäftsobjekt existiert (add<BusinessClass>()):
<BusinessClass> referencedObject;
statement = connection.prepareStatement(SELECT_<BusinessClass>_BY_PARENT_ID,
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
statement.setLong(1,id);
resultSet = statement.executeQuery();
while(resultSet.next()) {
referencedObject = new <BusinessClass>(resultSet.get<Type>(COLUMN_<Attribute-1>),
…);
businessObject.add<BusinessClass>(referencedObject);
Zählt ihr nun alle Artefakte zusammen, dann erhaltet ihr folgendes Ergebnis:
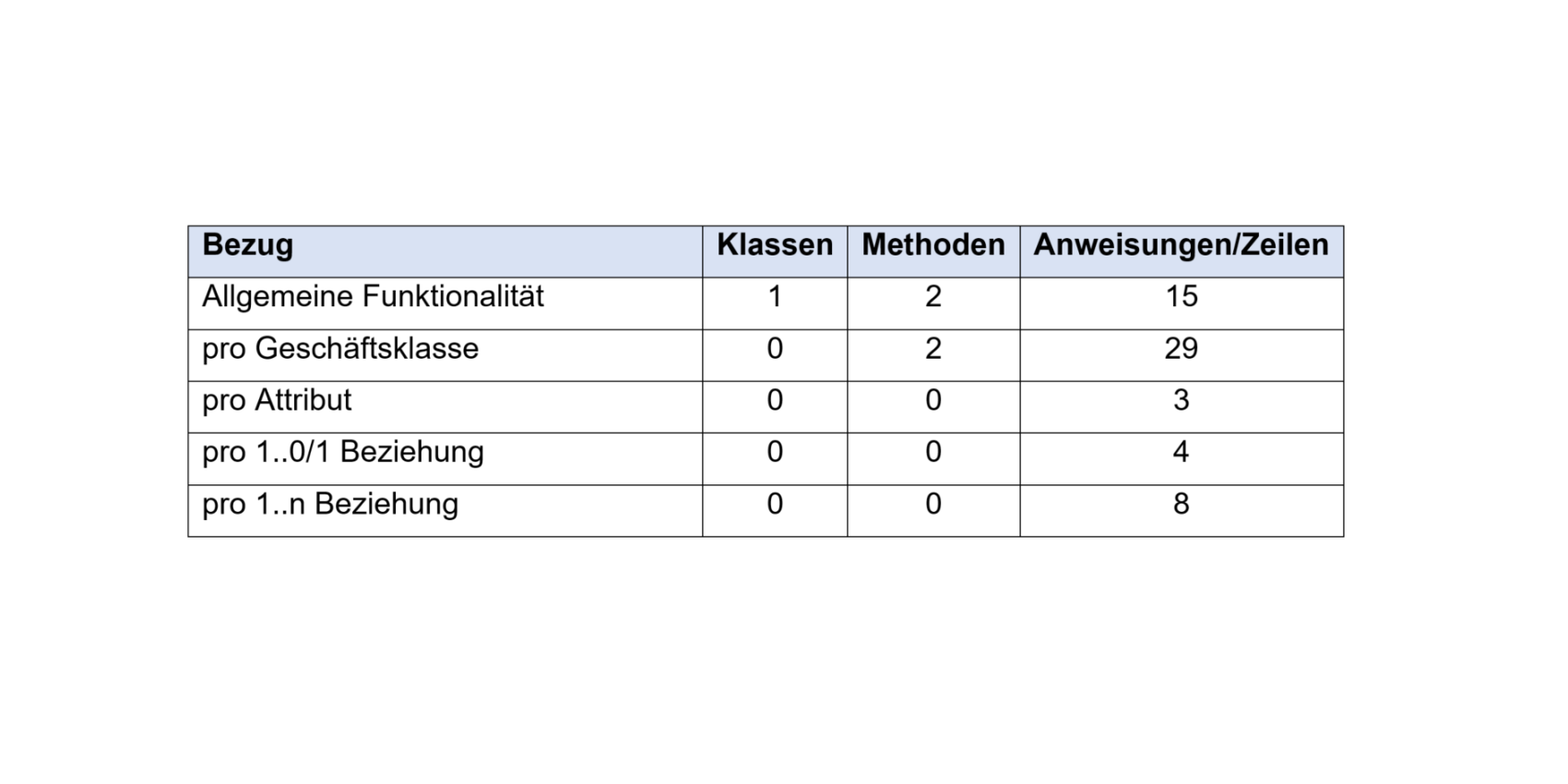
Fazit
Wie ihr gesehen habt, benötigt ihr bei der Implementierung mit JDBC zunächst eine Methode, um den technischen Schlüssel für ein Geschäftsobjekt aus der Datenbank über die Sequenz zu ermitteln. Ich hoffe, ich konnte euch diese erste Implementierungsmethode einfach und verständlich vorstellen.
Im zweiten Teil meines Blog-Beitrags gehe ich näher auf die Implementierungsvarianten „klassisches Hibernate“ und „JPA/Hibernate“ ein und vergleiche alle vorgestellten Varianten miteinander. Es bleibt also spannend.
Wenn ihr mehr zu interessanten Themen aus der adesso-Welt erfahren möchtet, dann werft doch auch einen Blick in unsere bisher erschienenen Blog-Beiträge.
Hier geht es zum zweiten Teil des Beitrags:
Fundierte Auswahl eines Frameworks – oder das haben wir immer schon so gemacht (Teil 2)

Kategorie: |
|
Schlagwörter: |
Framework |

