
3. Mai 2023 von Marc Mezger
Buzzword Bingo KI: Die wichtigsten Begriffe um bei KI mit reden zu können
Künstliche Intelligenz (KI)
Künstliche Intelligenz (KI) ist ein multidisziplinäres Gebiet der Informatik, das darauf abzielt, Maschinen und Software zu entwickeln, die in der Lage sind, menschenähnliche Intelligenz und Lern- und Problemlösungsfähigkeiten zu imitieren. KI-Systeme verwenden Algorithmen und Daten, um Informationen zu analysieren, Muster zu erkennen und Entscheidungen oder Vorhersagen zu treffen. Diese Technologie hat weitreichende Anwendungsmöglichkeiten, wie beispielsweise bei der Verarbeitung natürlicher Sprache, Bilderkennung, autonomen Fahrzeugen und personalisierten Empfehlungen, um nur einige zu nennen.

In diesem Bild ist die Hierarchie der verschiedenen Methoden für Künstliche Intelligenz zu sehen, Quelle: https://serokell.io/
ML (Maschinelles Lernen)
Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz, das sich darauf konzentriert, Algorithmen zu entwickeln, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen oder Entscheidungen zu treffen. Diese Algorithmen verwenden statistische Methoden, um Muster in den Daten zu erkennen und Modelle zu erstellen, die auf neue Daten übertragen werden können.
Beispiel-Algorithmen dafür sind: Entscheidungsbäume, Support-Vector-Maschinen oder Neuronale Netzwerke.
Neuronale Netze (NNs)
Ein Neuronales Netz ist ein künstliches System, das auf der Struktur und Funktionsweise des menschlichen Gehirns basiert und für Maschinelles Lernen und Künstliche Intelligenz entwickelt wurde. Es besteht aus einer Vielzahl von miteinander verbundenen Neuronen, die Informationen verarbeiten und weiterleiten. Jedes Neuron empfängt Eingabesignale, verarbeitet diese und gibt ein Ausgangssignal an andere Neuronen weiter. Durch den Trainingsprozess passt das Netzwerk seine Verbindungen und Gewichte an, um die Leistung bei einer bestimmten Aufgabe zu verbessern. Nach dem Training kann das Neuronale Netz komplexe Muster erkennen und Vorhersagen oder Entscheidungen basierend auf neuen Daten treffen.
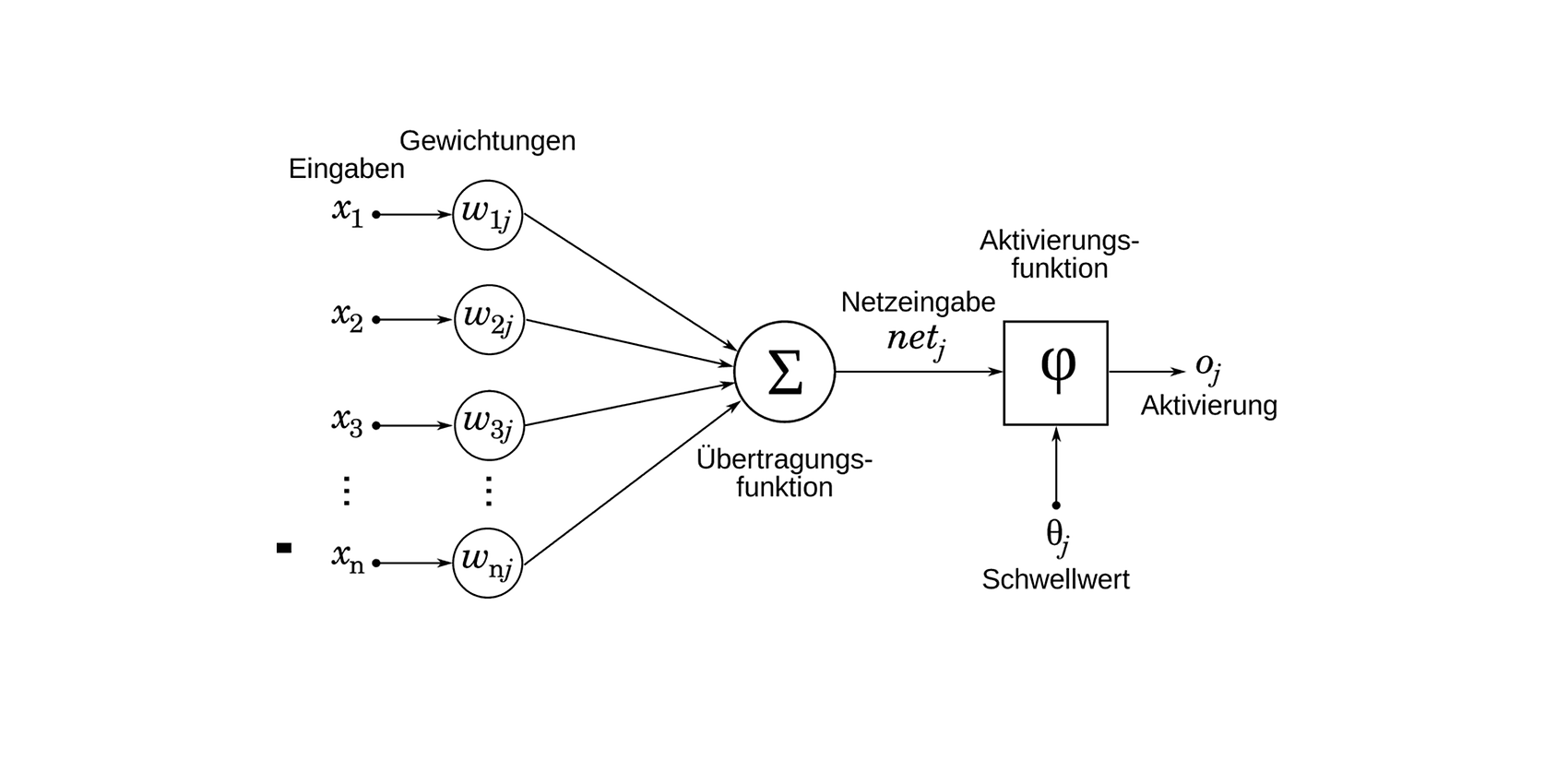
Ein Beispiel für ein Neuron, Quelle: https://datasolut.com/neuronale-netzwerke-einfuehrung/
Ein künstliches Neuron ist eine grundlegende Einheit in Neuronalen Netzen, die Eingaben verarbeitet, um eine Ausgabe zu erzeugen. Es besteht aus mehreren Komponenten:
- Inputs: Das Neuron empfängt Eingabesignale von anderen Neuronen oder externen Datenquellen. Jede Eingabe ist mit einem Gewicht assoziiert, das die Stärke der Verbindung repräsentiert.
- Gewichte: Die Gewichte sind Skalierungsfaktoren, die die Bedeutung einer bestimmten Eingabe für das Neuron bestimmen. Sie werden im Laufe des Trainingsprozesses angepasst.
- Übertragungsfunktion: Im Neuron werden die Eingabesignale mit ihren jeweiligen Gewichten multipliziert und anschließend aufsummiert, um einen gewichteten Summenwert zu erhalten.
- Bias: Ein Bias ist ein konstanter Wert, der der gewichteten Summe hinzugefügt wird, um die Verschiebung des Aktivierungsschwellenwerts zu steuern.
- Aktivierungsfunktion: Schließlich wird die gewichtete Summe (inklusive Bias) durch eine Aktivierungsfunktion geleitet, die die Ausgabe des Neurons bestimmt. Die Aktivierungsfunktion ist eine nichtlineare Funktion, die das Neuron dazu befähigt, komplexe Muster zu lernen und zu modellieren.
Die resultierende Ausgabe des Neurons kann dann an andere Neuronen im Netzwerk weitergeleitet werden, um die gewünschte Aufgabe auszuführen.
DL (Deep Learning)
Deep Learning ist eine Untergruppe des Maschinellen Lernens, die sich auf Neuronale Netzwerke mit vielen Schichten (tiefe Netzwerke) konzentriert, um komplexe Muster in Daten zu erkennen und zu lernen. Es ermöglicht automatisches, hierarchisches Lernen von abstrakten Merkmalen aus rohen Daten wie Bildern, Sprache und Text. Deep Learning ist verantwortlich für bedeutende Fortschritte in Bereichen wie Computer Vision und Sprachverarbeitung, zum Beispiel bei der Erkennung von Objekten in Bildern oder maschineller Übersetzung.
Wie lernt KI?
Künstliche Intelligenz lernt durch einen iterativen Prozess, der im Allgemeinen aus einer Trainings- und Testphase besteht. Hier ist eine kurze Erklärung des Lernprozesses:
- 1. Datenaufbereitung: Zunächst werden die verfügbaren Daten in Trainings-, Validierungs- und Testsets aufgeteilt. Das Trainingsset wird verwendet, um das KI-Modell zu trainieren, während das Testset dazu dient, die Leistung des Modells nach dem Training zu bewerten. Das Validierungsset wird während des Trainings verwendet, um das Modell zu optimieren. Anschließend werden weitere Schritte durchgeführt, wie Data Cleaning (Bereinigen der Daten, Entfernung von Nullwerten in den Daten etc.) und Normalisierung.
- 2. Training: In der Trainingsphase wird das KI-Modell mit den Trainingsdaten gefüttert. Das Modell macht Vorhersagen basierend auf den Eingaben und vergleicht sie mit den tatsächlichen Ausgaben (bei Überwachtem Lernen). Anschließend wird eine Verlustfunktion (Loss Function) verwendet, um den Fehler zwischen den Vorhersagen und den tatsächlichen Ausgaben zu quantifizieren.
- 3. Anpassung: Basierend auf dem berechneten Verlust passt das KI-Modell seine internen Parameter (zum Beispiel Gewichte in einem Neuronalen Netzwerk) an, um den Fehler in zukünftigen Vorhersagen zu reduzieren. Dieser Anpassungsprozess wird normalerweise durch einen Optimierungsalgorithmus wie Gradient Descent gesteuert.
- 4. Iteration: Die Schritte 2 und 3 (Training und Anpassung) werden wiederholt, bis eine bestimmte Anzahl von Iterationen (Epochen) erreicht ist oder die Leistung des Modells auf den Trainingsdaten ein gewünschtes Niveau erreicht.
- 5. Validierung: Sobald das Modell trainiert ist, wird es auf dem Testset getestet, um seine Leistung auf unbekannten Daten zu bewerten. Dies gibt einen Hinweis darauf, wie gut das Modell verallgemeinert und ob es möglicherweise Overfitting (zu gut an die Daten angepasst) oder Underfitting (zu schlecht an die Daten angepasst) aufweist.
- 6. Feinabstimmung und Evaluation: Falls erforderlich können Hyperparameter des Modells oder die Modellarchitektur angepasst und der Trainingsprozess wiederholt werden, um die Leistung weiter zu optimieren. Schließlich wird das optimierte KI-Modell zur Lösung der zugrunde liegenden Aufgabe eingesetzt.
Dieser Lernprozess kann je nach Art des KI-Modells (beispielweise Überwachtes, Unüberwachtes oder Bestärkendes Lernen) und der spezifischen Anwendung variieren, aber die Grundprinzipien des Trainings bleiben ähnlich.
Convolutional Neural Networks (CNNs)
Ein Convolutional Neural Network oder CNN ist eine Art künstliches Neuronales Netzwerk, das häufig für Bilderkennung und Bildsegmentierung verwendet wird. Es hat eine dem menschlichen Auge ähnliche Funktionsweise. Die grundlegenden Merkmale eines CNN sind:
Convolutional Layers: Diese Schichten führen eine Faltungsoperation durch, um Merkmale aus den Eingabedaten zu extrahieren. Sie verwenden Filter (auch als Kern bezeichnet), die über die Eingabedaten geschoben werden, um Muster und Strukturen zu erkennen.
Pooling Layers: Diese reduzieren die Dimensionalität der Convolutional Layers und machen die Merkmale robuster gegenüber kleinen Verschiebungen. Die häufigsten Pooling-Methoden sind Max Pooling und Average Pooling.

Convolutions, Quelle: Paperswithcode.com
Eine Convolution ist eine mathematische Operation, die zwei Eingaben kombiniert, um eine Ausgabe zu erzeugen. Bei einem CNN wird eine Convolution auf Bilder angewendet, um Bildmerkmale hervorzuheben.
Hier ist eine einfache Erklärung, wie eine Convolution auf einem Bild funktioniert:
- 1. Nehmt einen Filter (auch Kern oder Kernel genannt) – dies ist in der Regel eine kleine Matrix – mit beispielsweise 3x3 Pixel. Der Filter enthält Gewichte, die während des Trainings gelernt werden.
- 2. Legt den Filter über das Eingabebild. Der Filter wird Pixel für Pixel über das Bild geschoben, sowohl vertikal als auch horizontal.
- 3. Multipliziert für jeden Schritt die Filtergewichte mit den entsprechenden Pixelwerten im Eingabebild. Addiert dann alle diese Multiplikationen auf, um ein einzelnes Ausgabepixel zu erhalten.
- 4. Legt den Filter weiter über das Bild, bis der gesamte Bildbereich abgedeckt ist. Das Resultat ist eine neue Matrix mit Ausgabewerten – dies ist die Ausgabe der Convolution.
- 5. Die Ausgabe enthält nun Merkmale des Eingabebildes, die durch den Filter hervorgehoben werden. Zum Beispiel könnte ein vertikaler Filter vertikale Kanten hervorheben.
- 6. Mehrere Filter können nacheinander angewendet werden, wobei jeder Filter nach bestimmten Merkmalen sucht. Die Ausgaben werden zu „Kanälen“ oder „Feature Maps“ zusammengefasst.
- 7. Diese Feature Maps werden dann oft verkleinert oder gefiltert, indem ein Pooling Layer hinzugefügt wird. Dies macht die Merkmale robuster und reduziert die Datenmenge.
Weitere Details fidnet ihr in meinem Blog-Beitrag zum Thema „Computer Vision für Deep Learning – eine kurze Einführung“.
NLP (Natural Language Processing)
Natural Language Processing (NLP) ist der Bereich der Künstlichen Intelligenz, der sich mit der automatischen Verarbeitung und Analyse von natürlicher Sprache beschäftigt. NLP-Systeme können Sprache analysieren, verstehen und generieren. Ein Beispiel für NLP ist die automatische Übersetzung zwischen Sprachen oder die Frage-Antwort-Funktionalität in digitalen Assistenten wie Siri oder Alexa. Auch GPT-4 und ChatGPT oder Aleph Alphas Luminous sind Modelle für Natural Language Processing.
Reinforcement Learning (Bestärkendes Lernen)
Reinforcement Learning ist ein Machine-Learning-Ansatz, bei dem ein Agent durch Interaktion mit einer dynamischen Umgebung ohne explizite Instruktionen eines Lehrers lernt. Der Agent erhält Belohnungen und Bestrafungen als Feedback, um sein Verhalten zu verbessern.
Die grundlegenden Konzepte des Reinforcement Learning sind:
- Agent: Der lernende Algorithmus, der Aktionen in einer Umgebung ausführt. Der Agent verwendet seinen aktuellen Zustand und seine Lernstrategie, um Aktionen auszuwählen.
- Umgebung: Die Welt, in der der Agent agiert. Nach jeder Aktion des Agenten wird der Zustand der Umgebung aktualisiert. Die Umgebung stellt dem Agenten auch Belohnungen und Bestrafungen zur Verfügung.
- Zustand: Repräsentiert den aktuellen Stand der Umgebung. Enthält alle Informationen, die der Agent zur Entscheidungsfindung benötigt.
- Aktion: Eine vom Agenten ausgeführte Operation, die den Zustand der Umgebung beeinflusst.
- Belohnung: Feedback von der Umgebung, um dem Agenten anzuzeigen, wie gut seine letzte Aktion war. Die Belohnung bestimmt das Verhalten, das der Agent lernen soll.
- Episode: Eine Folge von Zuständen, Aktionen und Belohnungen vom Start bis zum Ende einer Interaktion. Endet, wenn ein Zielzustand erreicht wird.
- Ziel: Der gewünschte Zustand, den der Agent in der Umgebung erreichen soll. Wird durch die maximale Gesamtbelohnung in einer Episode definiert.
Der Agent passt seine Strategie so an, dass er im Laufe der Zeit die maximale Gesamtbelohnung erhält. So lernt der Agent die optimale Strategie, um das Ziel zu erreichen.
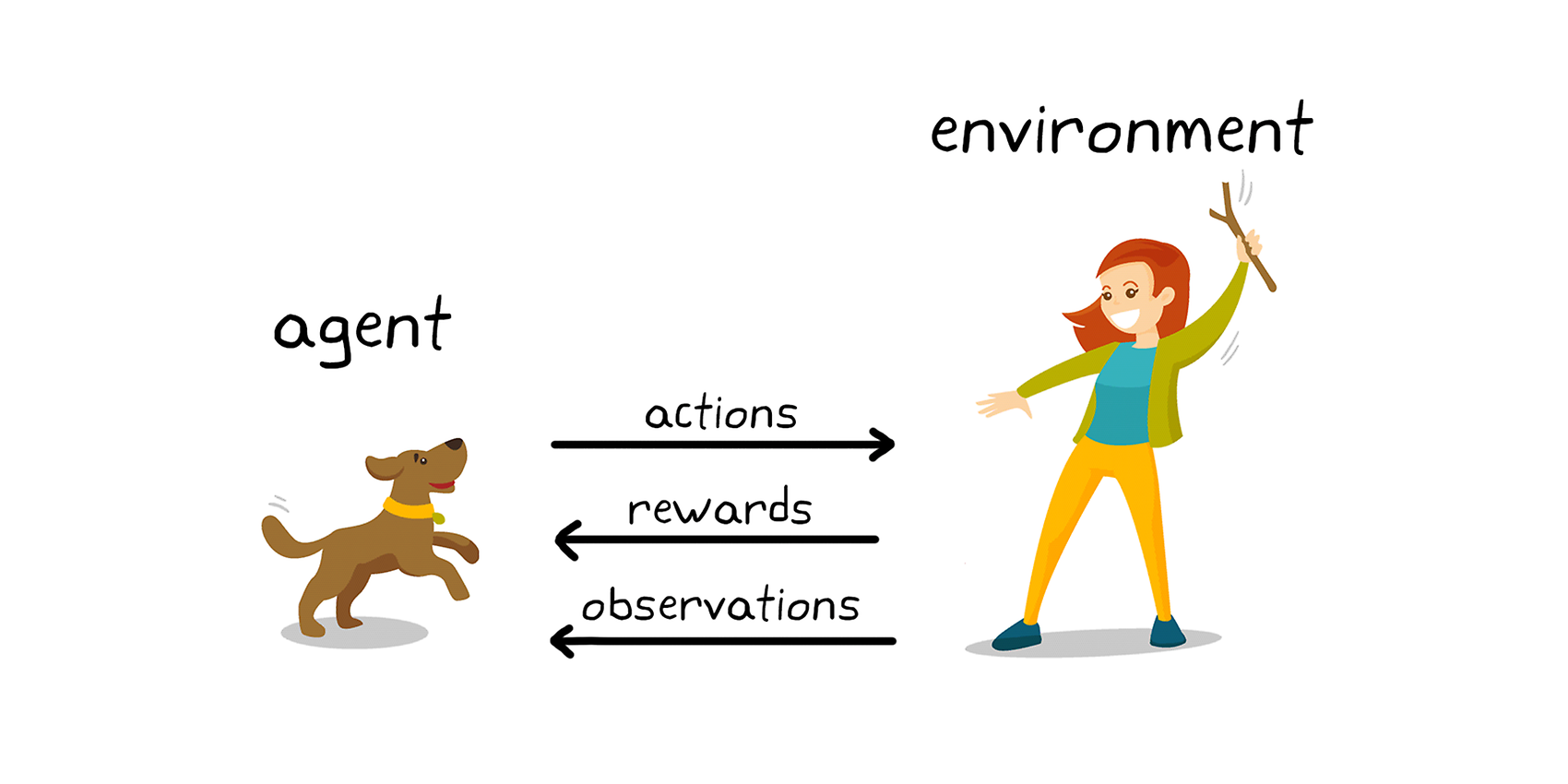
Ein einfaches Beispiel wie Reinforcement Learning funktioniert, Quelle: Matlab
Im Kontext des Reinforcement Learning und Hundetrainings sind die wichtigsten Punkte:
- 1. Agent: Der Hund ist der Agent, der im Laufe des Trainings bestimmte Fähigkeiten oder Verhaltensweisen erlernen soll.
- 2. Umgebung: Die Umgebung umfasst die Trainerin oder den Trainer und das Umfeld, in dem der Hund die Aufgaben bewältigen und auf die Kommandos der Trainerin oder des Trainers reagieren muss.
- 3. Beobachtung: Die Beobachtungen sind die Kommandos oder Hinweise, die die Trainerin oder der Trainer dem Hund gibt. Der Hund muss diese Beobachtungen verarbeiten und darauf basierend eine Entscheidung treffen, welche Handlung auszuführen ist.
- 4. Handlung: Die Handlung ist die Reaktion des Hundes auf das gegebene Kommando oder den Hinweis. Der Hund muss die richtige Handlung ausführen, um eine Belohnung zu erhalten.
- 5. Belohnung: Die Belohnung ist ein positiver Verstärker, der dem Hund gegeben wird, wenn er das gewünschte Verhalten zeigt. Dies kann ein Leckerbissen, ein Spielzeug oder Lob von der Trainerin oder vom Trainer sein.
- 6. Strategie: Die Strategie ist die Zuordnung zwischen den Beobachtungen (Kommandos) und den Handlungen, die der Hund im Laufe des Trainings lernt. Der Hund entwickelt eine interne Strategiefunktion, die ihm hilft, die richtige Handlung auszuführen, basierend auf den Beobachtungen, die er vom Trainer erhält.
Das Hauptziel des Trainings ist es, die Strategie des Hundes so zu gestalten, dass er das gewünschte Verhalten lernt und die entsprechenden Belohnungen erhält. Nach erfolgreichem Training sollte der Hund in der Lage sein, auf die Kommandos des Trainers zu reagieren und die richtigen Handlungen auszuführen, ohne dass ständig Belohnungen erforderlich sind. Der Hund wendet dabei die im Laufe des Trainings entwickelte interne Strategiefunktion an.
Computer Vision
Computer Vision ist ein Bereich der Künstlichen Intelligenz, der sich mit der automatischen Extraktion, Analyse und Verarbeitung von sinnvollen Informationen aus digitalen Bildern und Videos befasst. Computer Vision umfasst Teilaufgaben wie Klassifizierung oder Segmentierung (Klassifikation von Pixeln in Bildern). Computer-Vision-KI basiert oft auf Convolutional Neural Networks. Mehr Infos zu diesem Thema findet ihr in meinem Blog-Beitrag zum Thema „Computer Vision für Deep Learning – eine kurze Einführung“.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) sind eine spezielle Art von Neuronalen Netzen, die aus zwei Modellen bestehen: einem Generator und einem Diskriminator.
Der Generator ist dafür verantwortlich, neue Daten zu erzeugen, wie zum Beispiel Bilder. Er verwendet eine latente Repräsentation, die zufällig erzeugt wird, um daraus neue Daten zu generieren. Die erzeugten Daten sollen dabei so realistisch wie möglich aussehen.
Der Diskriminator bekommt sowohl echte Trainingsdaten als auch die künstlich vom Generator erzeugten Daten zu sehen. Seine Aufgabe ist es, diese voneinander zu unterscheiden. Er versucht die echten Daten richtig als real einzuordnen und die generierten Daten als „fake“ zu entlarven.
Generator und Diskriminator befinden sich in einem kontinuierlichen Wettbewerb, einem sogenannten „Nullsummenspiel“. Der Generator entwickelt sich weiter, indem er immer realistischere Daten erzeugt, um den Diskriminator zu täuschen. Der Diskriminator seinerseits verbessert seine Unterscheidungsfähigkeit, um die Fälschungen des Generators zu erkennen. Dieser Wettbewerb treibt beide Modelle zu immer besseren Leistungen an.
Die GANs sind eine vielversprechende Technologie mit vielen Anwendungsmöglichkeiten. Sie werden häufig zur Bildsynthese eingesetzt, können aber auch für andere Datentypen wie Text, Audio oder medizinische Daten verwendet werden. Sie zeigen sehr überzeugende Ergebnisse und ermöglichen es, riesige Mengen an realistischen synthetischen Daten zu generieren. Dies ist nützlich, wenn Trainingsdaten nur spärlich vorhanden sind. GANs sind ein hochaktives Forschungsgebiet mit vielen offenen Fragen, aber sie versprechen, eine wichtige Rolle in der Zukunft des Deep Learning zu spielen.

Quelle: https://www.simplilearn.com/tutorials/deep-learning-tutorial/generative-adversarial-networks-gans
Supervised Learning (Überwachtes Lernen)
Supervised Learning ist eine Form des Maschinellen Lernens, bei der die Trainingsdaten aus bereits vorhandenen Beispielen mit bekannten Ergebnissen bestehen. Das System lernt unter Anleitung durch diese beschrifteten Beispiele.

Ein Beispiel für Überwachtes Lernen, Quelle: https://www.epoq.de/blog/supervised-learning-ki-modell/
Unsupervised Learning (Unüberwachtes Lernen)
Unsupervised Learning ist eine Methode des Maschinellen Lernens, bei der ein Modell aus unbekannten, nicht etikettierten Daten lernt. Im Gegensatz zum Überwachten Lernen, wo die Trainingsdaten sowohl Eingabe- als auch Ausgabeetiketten enthalten, verfügen die Trainingsdaten beim Unsupervised Learning nur über Eingabeinformationen ohne zugeordnete Ausgabeetiketten.
Das Hauptziel von Unsupervised Learning besteht darin, Muster, Strukturen oder Zusammenhänge innerhalb der Daten zu erkennen. Zu den häufigsten Anwendungen gehören Clustering, bei dem ähnliche Datenpunkte in Gruppen eingeteilt werden, und Dimensionsreduktion, bei der die Anzahl der Merkmale reduziert wird, um die Daten besser zu visualisieren oder zu analysieren.
Da Unsupervised Learning ohne menschliche Anleitung auskommt, kann es besonders nützlich sein, wenn große Mengen an unstrukturierten oder ungelabelten Daten verfügbar sind und es schwierig oder zeitaufwendig wäre, manuell Labels (Klassen) zu erstellen.

Ein Beispiel für Clustering von Daten basiert auf Abständen und Häufungen, Quelle: https://deepai.org/
Transfer Learning
Transfer Learning ist eine Technik im Maschinellen Lernen, bei der ein bereits auf eine bestimmte Aufgabe oder einen Datensatz trainiertes Modell als Ausgangspunkt verwendet wird, um ein neues, ähnliches Problem schneller und mit weniger Trainingsdaten zu lösen. Dabei werden die erlernten Merkmale und Strukturen des ursprünglichen Modells auf das neue Problem übertragen und angepasst.
Der Prozess des Transfer Learnings umfasst in der Regel die folgenden Schritte:
- 1. Auswahl eines vortrainierten Modells, das bei einer ähnlichen oder verwandten Aufgabe erfolgreich war.
- 2. Anpassung des Modells an das neue Problem, zum Beispiel durch Hinzufügen oder Ändern von Schichten in einem Neuronalen Netzwerk oder Anpassen der Modellparameter.
- 3. Training des angepassten Modells auf dem neuen, kleineren Datensatz, oft mit einer geringeren Lernrate, um die bereits erlernten Merkmale nicht zu stark zu beeinflussen.
Transfer Learning ist besonders nützlich, wenn nicht genügend Trainingsdaten für das neue Problem vorhanden sind oder das Training eines neuen Modells von Grund auf zu zeitaufwendig oder rechenintensiv wäre. Es ist weit verbreitet in Bereichen wie Bild- und Spracherkennung, da hier vortrainierte Modelle auf große, allgemeine Datensätze wie ImageNet oder Wikipedia angewendet werden können.

Ein Beispiel für eine Anwendung von Transfer Learning, ein CNN das zuerst auf Alltäglichen Bildern Trainiert wurde um dann Krebs zu klassifizieren, Quelle: https://www.mdpi.com/1424-8220/23/2/570
Ich hoffe, ich konnte ein weing Licht ins Dunkle bringen und euch einige Buzzwords und Konzepte, die im KI-Bereich relevant sind, einfach und verständlich erklären.
Alles rund um das Thema Künstliche Intelligenz bei adesso findet ihr auf unserer Website.
Weitere spannende Themen aus der adesso-Welt findet ihr in unseren bisher erschienen Blog-Beiträgen.
Auch interessant:

Kategorie: |
|
Schlagwörter: |
Künstliche Intelligenz (KI) |

