
8. März 2018 von Robert Brem
One-Click Deployment
Nehmen wir an, in einem Projekt gibt es diverse unabhängige Services, die jeweils ihre eigenen Release-Zyklen haben. Euer Kunde möchte nun diese Services miteinander verbinden und automatisieren, um die manuellen Prozesse sowie die Lead Time zu minimieren. Das führt zu einer Microservice-Architektur mit vielen kleinen Services, die ihr unabhängig voneinander testen und deployen müsst. Wie könnte der optimale Lösungsweg für eine solche Projektanforderung aussehen? In meinem Blog-Beitrag verrate ich es euch.
Die Verbesserung des Softwareauslieferungsprozesses mit Continuous Delivery
Für eine Verbesserung des Softwareauslieferungsprozesses – also des Deployments – empfehle ich euch Continuous Delivery. Damit ist eine Sammlung von Techniken, Prozessen und Werkzeugen gemeint, die das Deployment mit sehr geringem Risiko und zu jeder Zeit mit lediglich einem Knopfdruck ausführen kann.
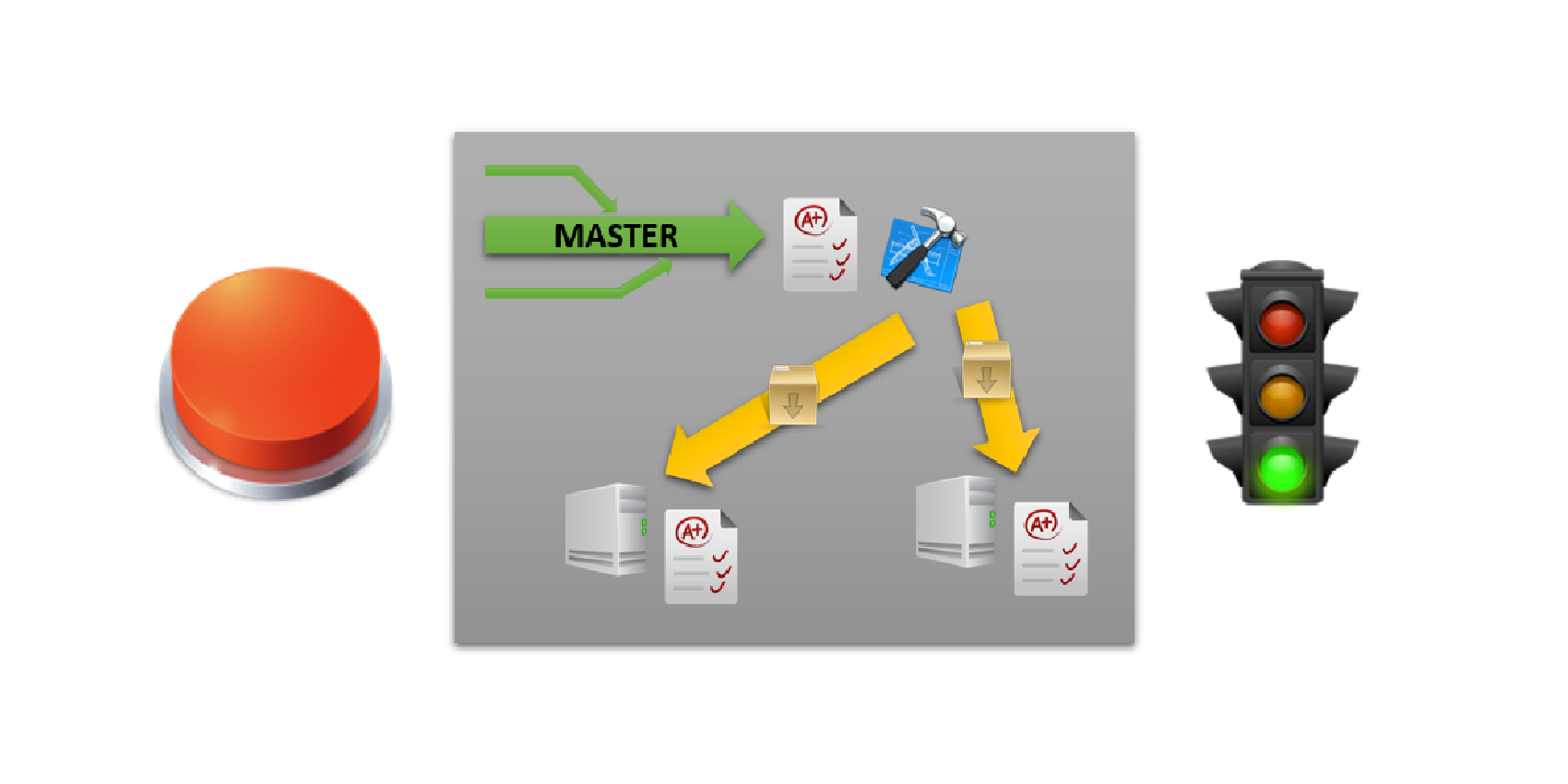
Continuous Delivery
Der Master Branch der Versionsverwaltung – darunter könnt ihr euch eine Hauptdatei vorstellen − ist dabei immer in einem Zustand, in dem er released werden könnte. Fehler, die ihr im Master Branch findet, haben die höchste Priorität und müssen sofort behoben werden.
Um einen praktischen Vergleich zu ziehen, könnt ihr dieses Vorgehen mit dem Andon-Cord des Toyota-Produktionssystems vergleichen. Hierbei handelt es sich um eine physische Reißleine, die zu jeder Zeit von jedem eurer Projektmitarbeiter „gezogen“ werden kann. Diese Methode hat den sofortigen Anlagenstopp zur Folge. Die Produktionsanlage wird erst wieder gestartet, wenn der Fehler behoben wurde. Somit sind alle Mitarbeiter bis zur Lösung des Problems blockiert, was eine schnelle Problemlösung bewirkt und so die Lead Time – also den Zeitraum zwischen erstem und letztem Arbeitsvorgang – verkürzt. Wie ihr in eurem Projekt ein ähnliches Vorgehen nutzen könnt, werde ich euch noch zeigen. Kommen wir zunächst einmal zur Lead Time.
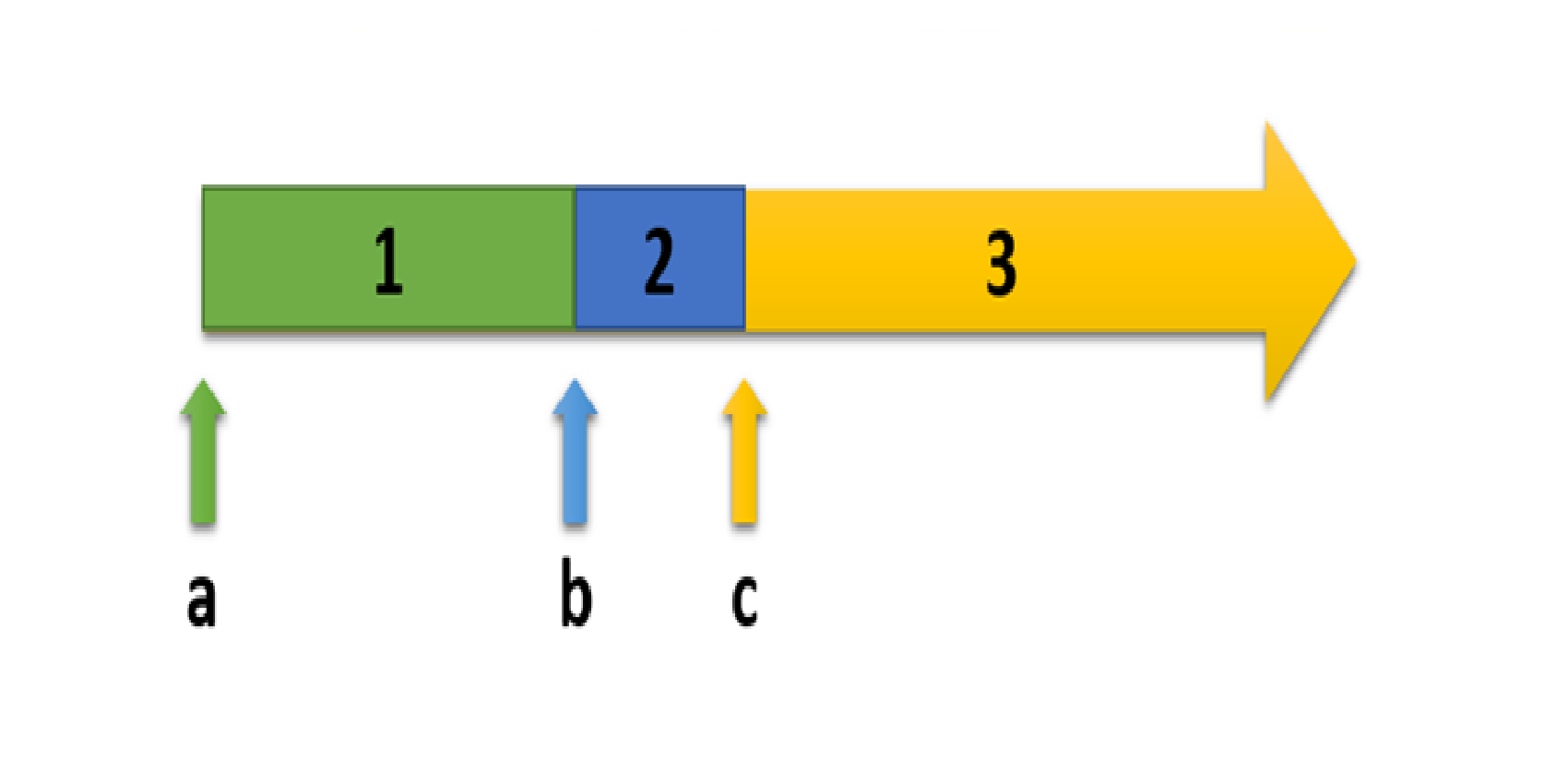
Darstellung einer Lead Time
- Den Beginn der Anforderung markiert der grüne Pfeil (a).
- Der blaue Pfeil (b) kennzeichnet den Zeitpunkt, an dem ihr mit der Implementation beginnt.
- Der gelbe Pfeil (c) gibt die Fertigstellung des Artefakts an.
Während der grünen (1) und gelben (3) Phase wird nichts an der tatsächlichen Umsetzung gemacht. Das hört sich erstmal etwas komisch an, ist aber tatsächlich so. Diese beiden Phasen werden nämlich dazu genutzt, um das Ticket zu bearbeiten (1) beziehungsweise um das fertige und getestete Artefakt im Release auszuspielen. Die eigentliche Konzeption – die sogenannte Process Time − fällt in den mittleren Bereich (2).
Die Lead Time solltet ihr übrigens so gering wie möglich halten, um zeitliche und finanzielle Ressourcen zu sparen – diesen Aspekt beschrieb Eliyahu M. Goldratt bereits in seiner 1984 erschienen Publikation „The Goal“.
Der technische Aspekt von Continuous Delivery
Ich empfehle euch, die Anforderungen an Continuous Delivery technisch mit Jenkins Pipelines umzusetzen. Die webbasierte Software Jenkins hat die Vorteile, dass sie weitverbreitet ist und euch eine große Community bietet, die schnell und zuverlässig bei Problemen hilft. Verfügt euer Team bereits über ein gewisses Maß an Erfahrung mit Jenkins aus vorherigen Projekten, ist das ein weiterer entscheidender Vorteil.
Eine Jenkins Pipeline besteht aus mehreren Stages, wobei ein Stage aus einzelnen Anweisungen besteht. Hier sind eurem Team keinerlei Grenzen gesetzt und es können beliebige Shell- oder Batch-Befehle abgesetzt werden. Diese könnt ihr wiederum in einem Stage zu einem logischen Prozessschritt zusammenfassen.

Stages einer Pipeline
Der oben gezeigte Ausschnitt einer Pipeline enthält folgende Stages: build and test, undeploy on dev, deploy on dev, system tests und continue on test.
Implementation
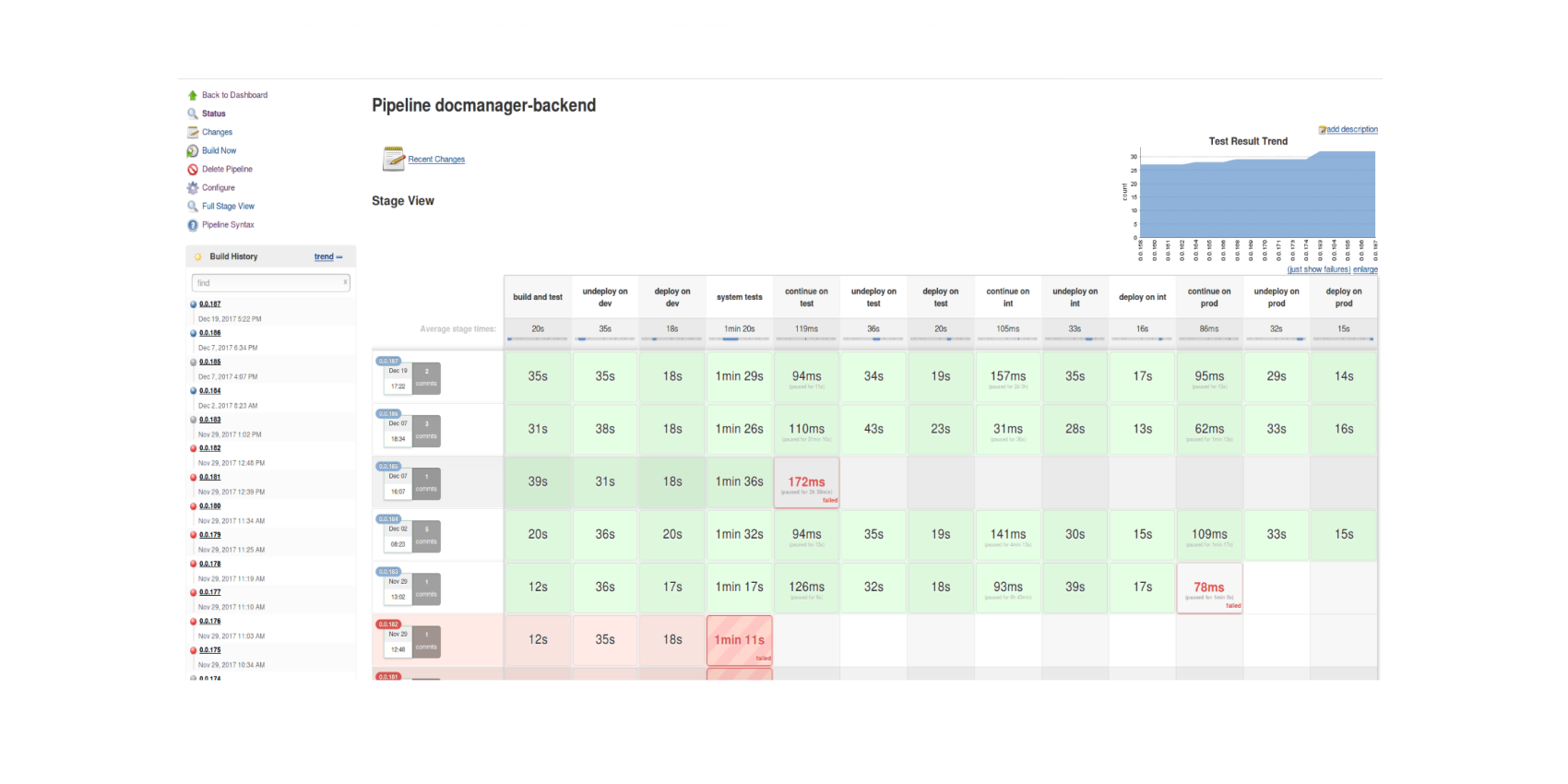
Pipeline mit mehreren Builds
Die Stages der Development-Umgebung werden direkt nach dem Start automatisch sequenziell ausgeführt. Schlägt ein Stage fehl, wird die Pipeline sofort angehalten und befindet sich im Zustand „failed“.
Wie auch in der Produktionsanlage, in der das Prinzip des oben beschriebenen Andon-Cords zum Einsatz kommt, sind nun auch in eurem Projekt alle Umgebungen für jegliche Deployments gesperrt, bis der Fehler behoben ist.
Fehlgeschlagener Build
Damit ihr etwas in Produktion ändern könnt, muss zunächst die gesamte Pipeline durchlaufen werden. Dadurch weiß jedes eurer Teammitglieder ganz genau, was auf welcher Umgebung installiert ist. Zudem habt ihr eine Garantie, dass die Qualität genau den Anforderungen an die entsprechende Umgebung entspricht.
Bevor eine Version auf die nächste Umgebung installiert wird, wartet die Pipeline auf die manuelle Freigabe durch einen berechtigten Benutzer. Möchtet ihr eine bestimmte Version noch nicht auf der nächsten Umgebung installieren, ist es durchaus legitim, dass ihr die Pipeline abbrecht und auf eine neue Version wartet.
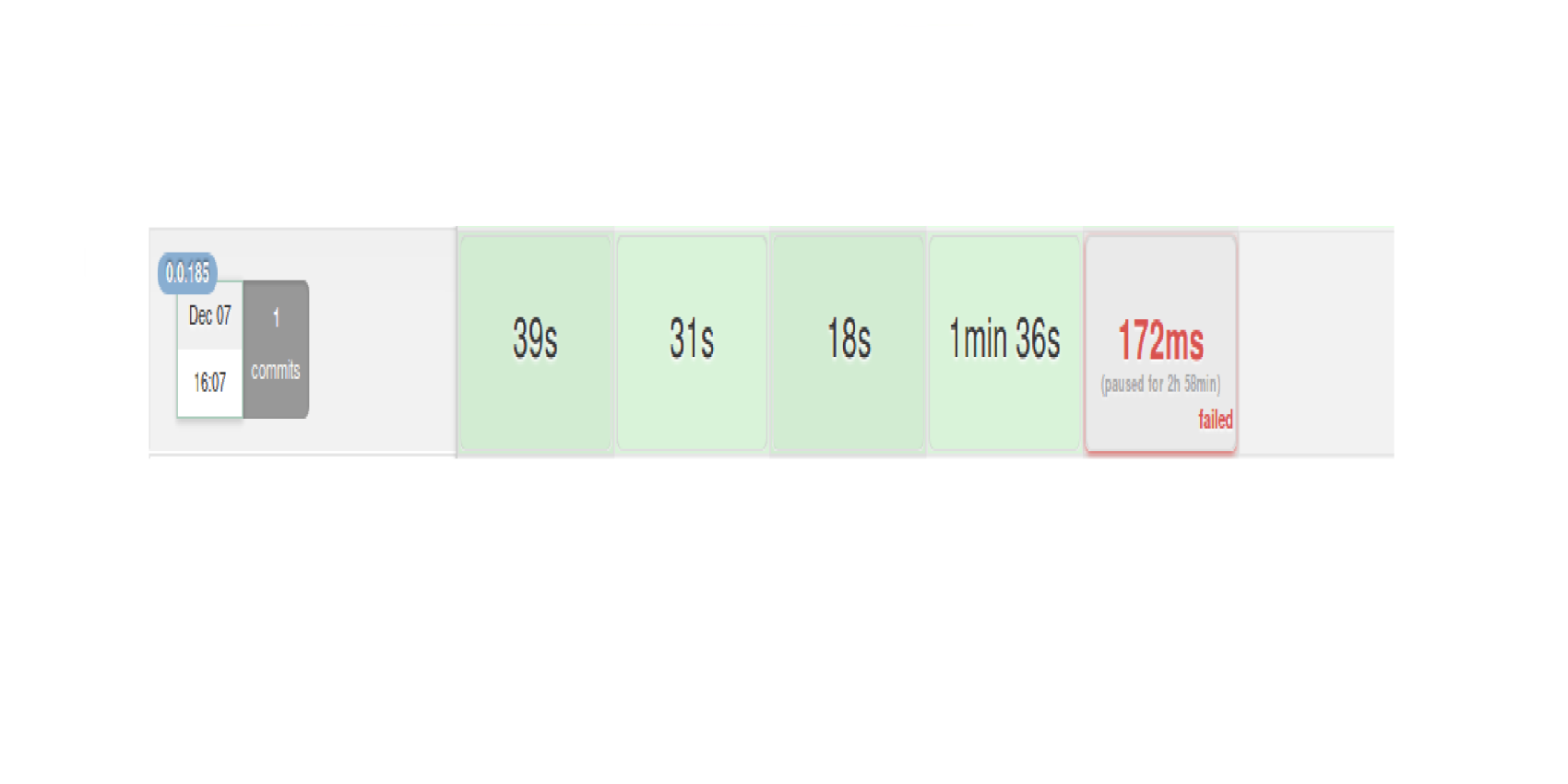
Abgebrochener Build
Um die Feedback-Zyklen noch weiter zu verkürzen, solltet ihr versuchen, so viel wie möglich davon zu automatisieren. Wie ihr das ohne viel Aufwand tun könnt, erkläre ich euch:
Lasttests
Lasttests sind Softwaretests, die eine sehr hohe Last auf dem zu testenden System erzeugen und dessen Verhalten untersuchen. Um zu vermeiden, dass ihr die Lasttests manuell durchführen müsst – wie ihr euch denken könnt, nimmt diese Vorgehensweise viel Zeit in Anspruch – solltet ihr JMeter-Lasttests erstellen, die jeweils automatisch nach den Systemtests ausgeführt werden. Bei JMeter handelt es sich um ein in Java geschriebenes Tool zum Ausführen von Lasttests. Wenn ihr euch weiter mit diesem Thema beschäftigen möchtet, werft doch einen Blick auf die Website von Apache JMeter.
Driven Contract Tests
In einer Microservice-Architektur ergibt sich oft die Situation, dass sich verschiedene Parteien auf eine Schnittstelle einigen müssen, die dann wiederum von diversen anderen Services konsumiert wird.
Das hat zur Folge, dass bei Anpassungen dieser Schnittstelle viel Kommunikationsaufwand zwischen euren einzelnen Teams notwendig wird. Um diesen Aufwand auf ein Minimum zu reduzieren, habt ihr die Möglichkeit, Consumer Driven Contract Tests einzusetzen. Dabei handelt es sich im Grunde genommen um weitere Systemtests, die ihr zusätzlich in die Pipeline einbaut. Das Besondere an diesen Tests ist, dass jedes Team, das an demselben System mitarbeitet, Schreibrechte auf diesem Repository hat.
Schlägt ein solcher Test fehl, muss das Team, das den Service besitzt, entscheiden, ob wirklich ein Fehler oder ein Missverständnis bei der Verwendung des Services vorliegt. Bei letzterem muss ein solches Missverständnis zunächst aufgelöst werden, denn ansonsten steht die Pipeline still und ihr könnt keine Änderung deployen.
Fazit
Wie ihr gesehen habt, löst ihr, wenn ihr das Ziel von schnellen Feedback-Zyklen erreichen möchtet, an diversen Stellen Abhängigkeiten aus. Genau das birgt dann auch eine gewisse Gefahr. Legt beispielsweise in einem bestimmten Team niemand Wert auf Qualität, ist das für Außenstehende sehr schwer zu erkennen. Der Source Code wird schließlich nur teamintern ausgechecked. Ist eines eurer Teams nicht zur Kommunikation mit weiteren Teams bereit, könnte es ein Indikator für Qualitätsprobleme sein. Üblicherweise tauschen sich verschiedene Teams nämlich oft untereinander aus, da viele Anforderungen in anderen Services schon einmal umgesetzt wurden.
Stellt ihr also fest, dass sich eines eurer Teams zurückzieht, empfehle ich euch, diesen Rückzug mit teamübergreifenden Codereviews oder Pair Programming – hier arbeiten zwei Entwickler an einem Rechner – entgegenzuwirken. Auf diese Weise könnt ihr mögliche Qualitätsprobleme früh erkennen und rechtzeitig beseitigen. Zudem profitieren die Teams untereinander von den bereits gemachten Erfahrungen.

Kategorie: |
|
Schlagwörter: |
- |

