
3. August 2022 von Moritz Michel
Frustriert durch Legacy-Code? at|analyze bietet erste Hilfe bei der Transformation und einen Durchblick im Legacy-System
Ein praktisches Anwendungsbeispiel einer Neo4J-Graphdatenbank
Cobol? Copybook? Assembler? JCL? Viele schalten bei diesen Begriffen schon ab. Kaum verwunderlich, wenn man bedenkt, dass die Geschichte von Cobol bis zum Jahr 1959 reicht.
Wenn man an Legacy-Code denkt, denkt man an Frustration, Angst vor Änderungen und überproportionale Komplexität. Für ein Unternehmen bedeutet es aber auch die Chance auf einen digitalen Wandel. Eine Chance auf Transformation eines Systems, das seit Dekaden gewachsen ist, zu einem System, das auf einem wichtigen Grundstein errichtet wurde: sauberer Software-Architektur. Damit ihr einen Überblick über euer Legacy-System erhaltet, ist eine tiefgehende Analyse unumgänglich.
Einsatz von Neo4J bei at|analyze
Wie ihr euch mit dem Analysewerkzeug at|analyze und einer Neo4J-Graphdatenbank einen Überblick über ein Legacy-System verschafft, erkläre ich euch:
Neo4J gehört zu der Gattung der NoSQL-Datenbanken. Was bedeutet NoSQL? NoSQL steht für „Not only SQL“ und für Datenbanksysteme, die mit den Eigenschaften typischer relationaler Datenbanken brechen. Dank der fehlenden starren Schemata der relationalen Datenbanken sind NoSQL-Systeme sehr flexibel einsetzbar und eignen sich für große Datenmengen.
In dem Anwendungsfall von at|analyze gibt es einen großen Vorteil einer Graphdatenbank gegenüber relationalen Datenbanksystemen: die vereinfachte Abbildung hierarchischer sowie vernetzter Strukturen. Neo4J ist also prädestiniert dafür, komplexe Programmstrukturen von Legacy-Systemen abzubilden.
Was ist Cypher?
So wie SQL die Standard-Abfragesprache für relationale Datenbanken ist, ist Cypher eine offene, herstellerübergreifende Abfragesprache für Graph-Technologien. In Neo4J wird die Cypher-Query-Language benutzt. Sie ist eine deklarative Graph-Query-Language, die ausdrucksstarke und effiziente Abfragen sowie Aktualisierung und Verwaltung von Graphen ermöglicht.
Cypher entstand durch die Inspiration von unterschiedlichen Sprachen. Viele der Schlüsselwörter wie WHERE und ORDER BY sind von SQL inspiriert. Das Pattern-Matching entlehnt Ausdrucksansätze von SPARQL. Einige der Listensemantiken sind Sprachen wie Haskell und Python entlehnt.
Aufbau Neo4J: Node, Relation, Label und Eigenschaften
Der Startpunkt eines Graphen ist ein Node. Nodes bilden die Entitäten einer Domäne ab. Sie können keine oder mehrere Labels und Eigenschaften besitzen. Durch Labels können Nodes in Sets gruppiert (also klassifiziert) werden. Außerdem können Nodes keine oder mehrere Relationen besitzen.
Der einfachste abzubildende Graph wäre ein einzelner Node ohne Relation.
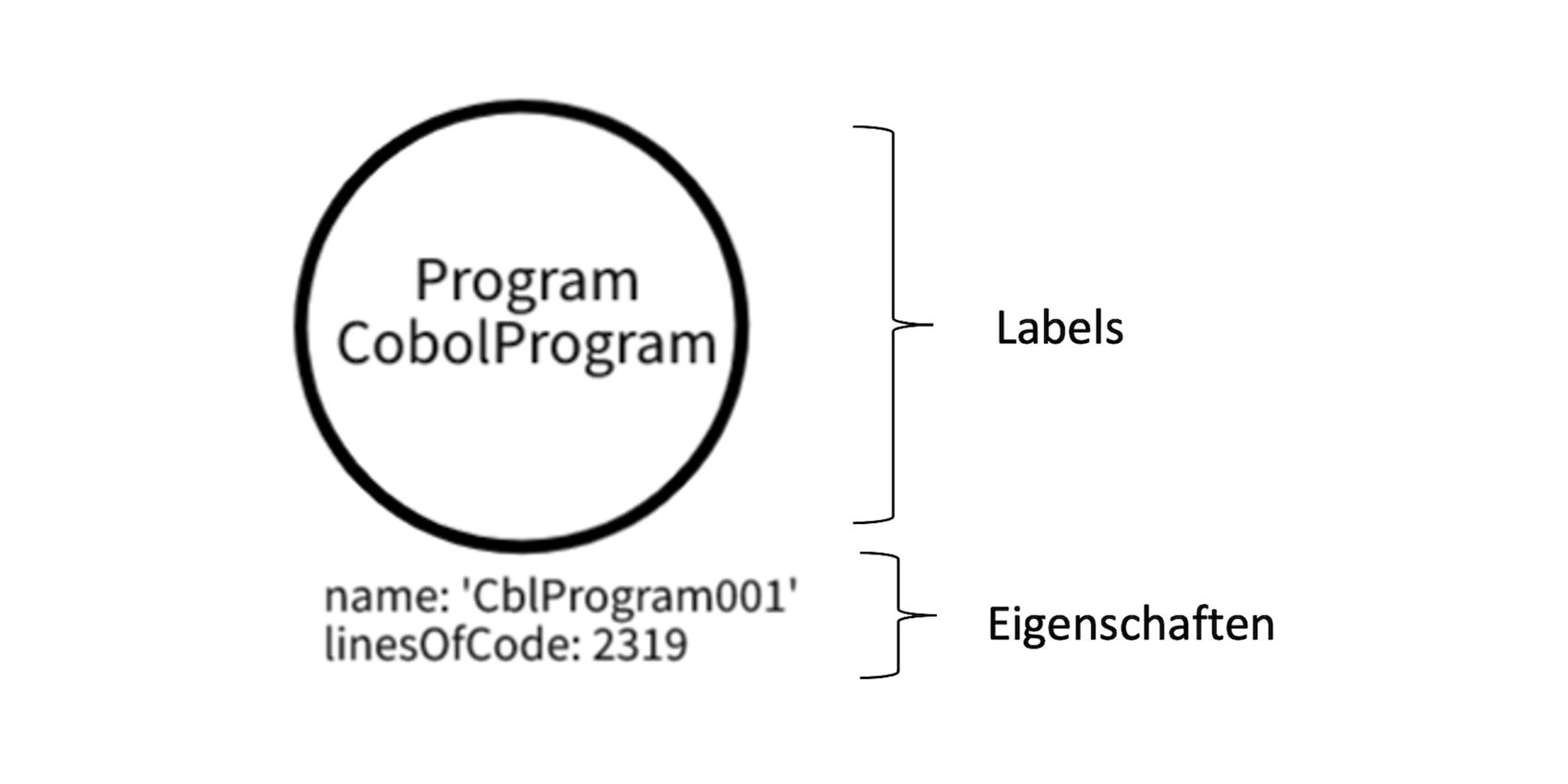
Aufbau eines Neo4J-Nodes
Die Labels sind „Program“ und „CobolProgram“, die Eigenschaften „name: 'CblProgram001'“ und „linesOfCode: 2319“.
Ein etwas komplexerer Graph wären zwei Cobol-Programme, die durch mehrere Nodes und Relationen verbunden sind:
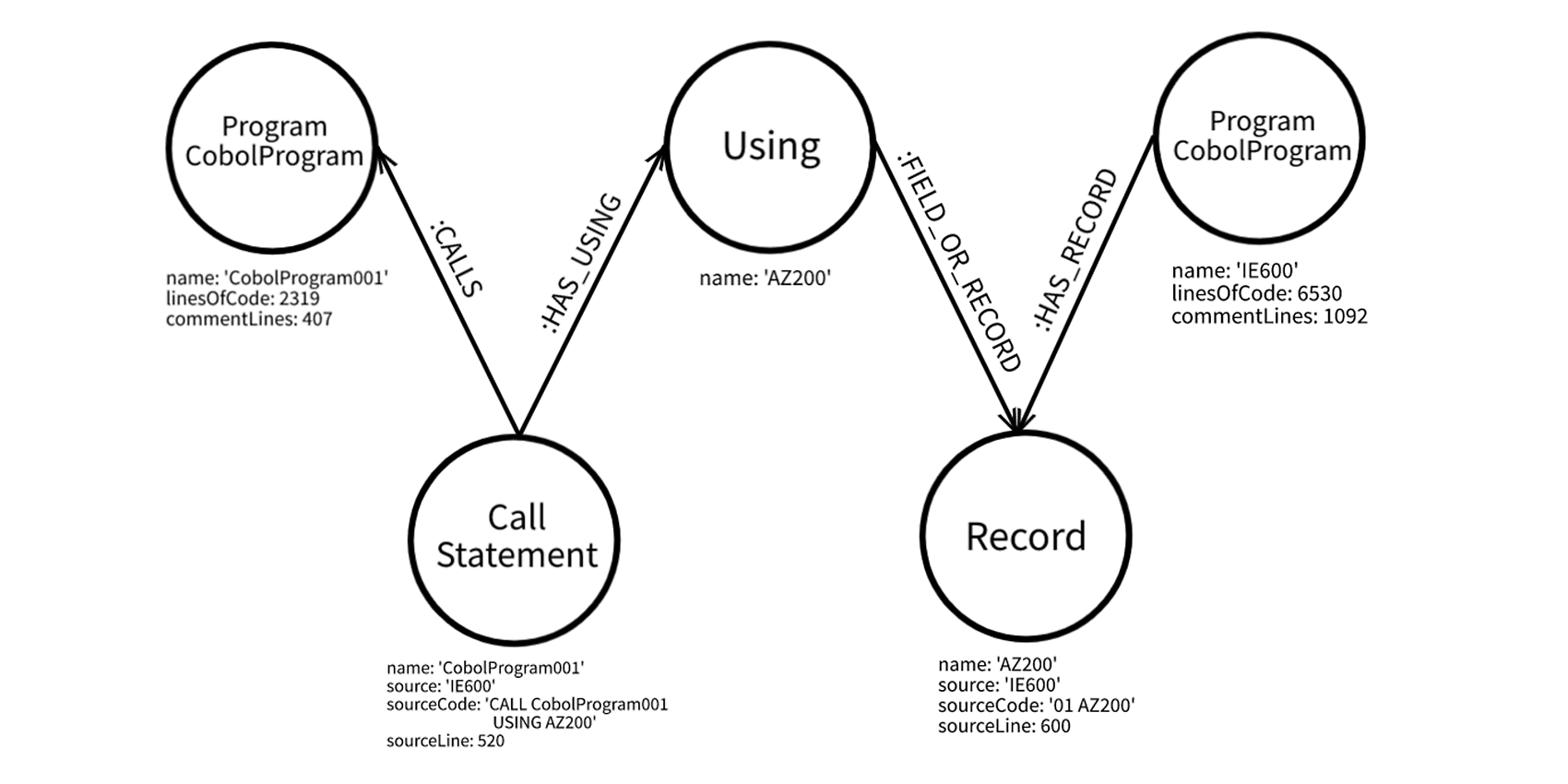
Komplexer Graph mit mehreren Nodes und Relationen
An diesem Beispiel erkennt ihr, dass immer eine Relation zwischen einem Source Node und einem Target Node herrscht. Ein Node kann allerdings auch mehrere Relationen zu anderen Nodes besitzen. So könnte beispielsweise das Cobol-Programm „CobolProgram001“ nicht nur eine Relation zu einem Call besitzen, sondern auch zu weiteren Calls/Usings/Records.
Dem Graphen kann nur entnommen werden, dass der Call „CobolProgram001“ das Cobol-Programm „CobolProgram001“ mit dem Record „AZ200“ aufruft. Dieser Record wird auch von dem Cobol-Programm „IE600“ verwendet.
Cypher versus SQL
Da wir nun unser Datenmodell kennengelernt haben, werden nun beispielhaft Querys in SQL und analog dazu die Cypher Query aufgelistet.
Einfaches Auslesen von Programm-Namen (erst SQL, dann Cypher):
SELECT program.name
FROM cobol_program;
MATCH (cobol:CobolProgram)
RETURN cobol.name;
In Cypher matchen wir das Label „CobolProgram“ auf „cobol“, können im RETURN-Statement „cobol“ adressieren und auf die Eigenschaften des Nodes zugreifen.
Einfacher Join von Calls, die ein Cobol-Programm aufrufen:
SELECT program.name, call.name
FROM cobol_program
JOIN calls AS calls ON calls.program_id = cobol_program.id
JOIN call ON calls.call_id = call.id;
MATCH (cobol:CobolProgram)<-[:CALLS]-(call:Call)
RETURN cobol.name, call.name
In dem Join-Beispiel wird das Label „CobolProgram“ auf „cobol“ und „Call“ auf „call“ gematcht. Dadurch können im RETURN-Statement „cobol“ sowie „call“ adressiert und so kann auf die Eigenschaften der Nodes zugegriffen werden. Mit „<-[:CALLS]-“ definiert ihr, welche Beziehung besteht und in welche Richtung sie verläuft.
Ihr erkennt anhand des zweiten Beispiels eine Tendenz: SQL ist für relationale Datenbankmodelle optimiert, aber sobald es komplexe, beziehungsorientierte Abfragen verarbeiten muss, werden die Querys größer. In diesen Fällen liegt das Grundproblem nicht bei SQL, sondern beim relationalen Modell selbst, das nicht für die Verarbeitung graphartig verbundener Daten ausgelegt ist.
Für Domänen mit stark vernetzten Daten ist das Graphmodell empfehlenswert und folglich auch eine Graph-Abfragesprache wie Cypher. Wenn man Erfahrungen in SQL sammeln konnte, ist Cypher aber leicht zu erlernen.
Was macht at|analyze genau?
Die Assembler-, JCL- und Cobol-Programme werden zunächst eingelesen. Dies wird durch einen Import in at|analyze realisiert. Das Herzstück des Imports sind verschiedene Parser. Diese analysieren den Source Code und trennen den tatsächlichen Code von anderen Dingen wie Kommentaren.
Nach der Phase des Parsens steigen die Resolver ein und lösen die Abhängigkeiten/Relationen zwischen Programmen beziehungsweise Programmteilen auf.
Im Anschluss können wir uns im Dashboard von at|analyze einen allgemeinen Überblick verschaffen.
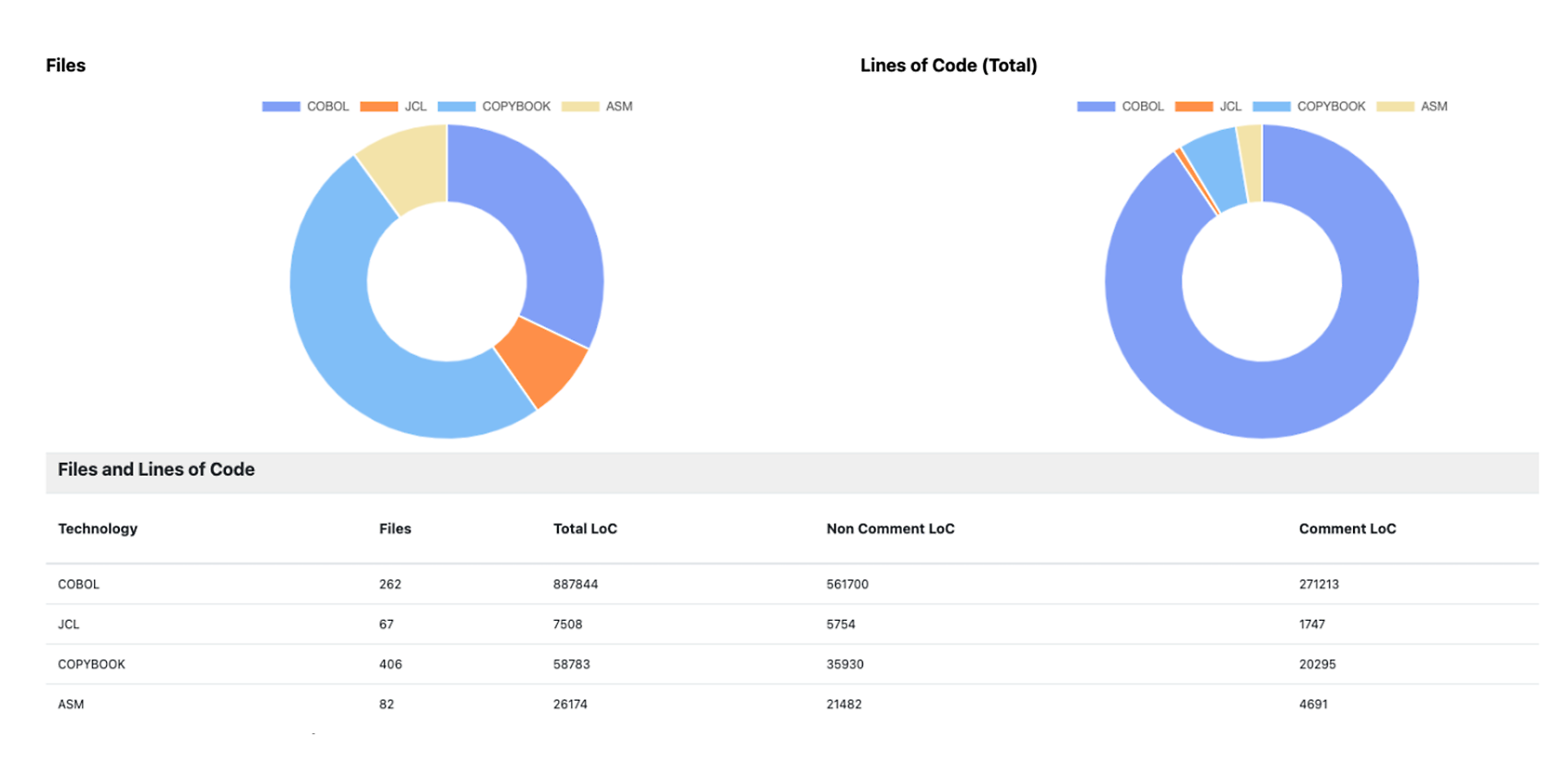
Dashboard von at|analyze
Neben dem Dashboard können wir uns auch die Detailseite eines analysierten Programms anzeigen lassen. Öffnen wir den Call-Graph-Reiter eines Cobol-Programms auf der Detailseite, sehen wir den komplexen Aufbau des analysierten Programms. Im folgenden Beispiel seht ihr ein Cobol-Programm mit ca. 16.000 Zeilen Code.
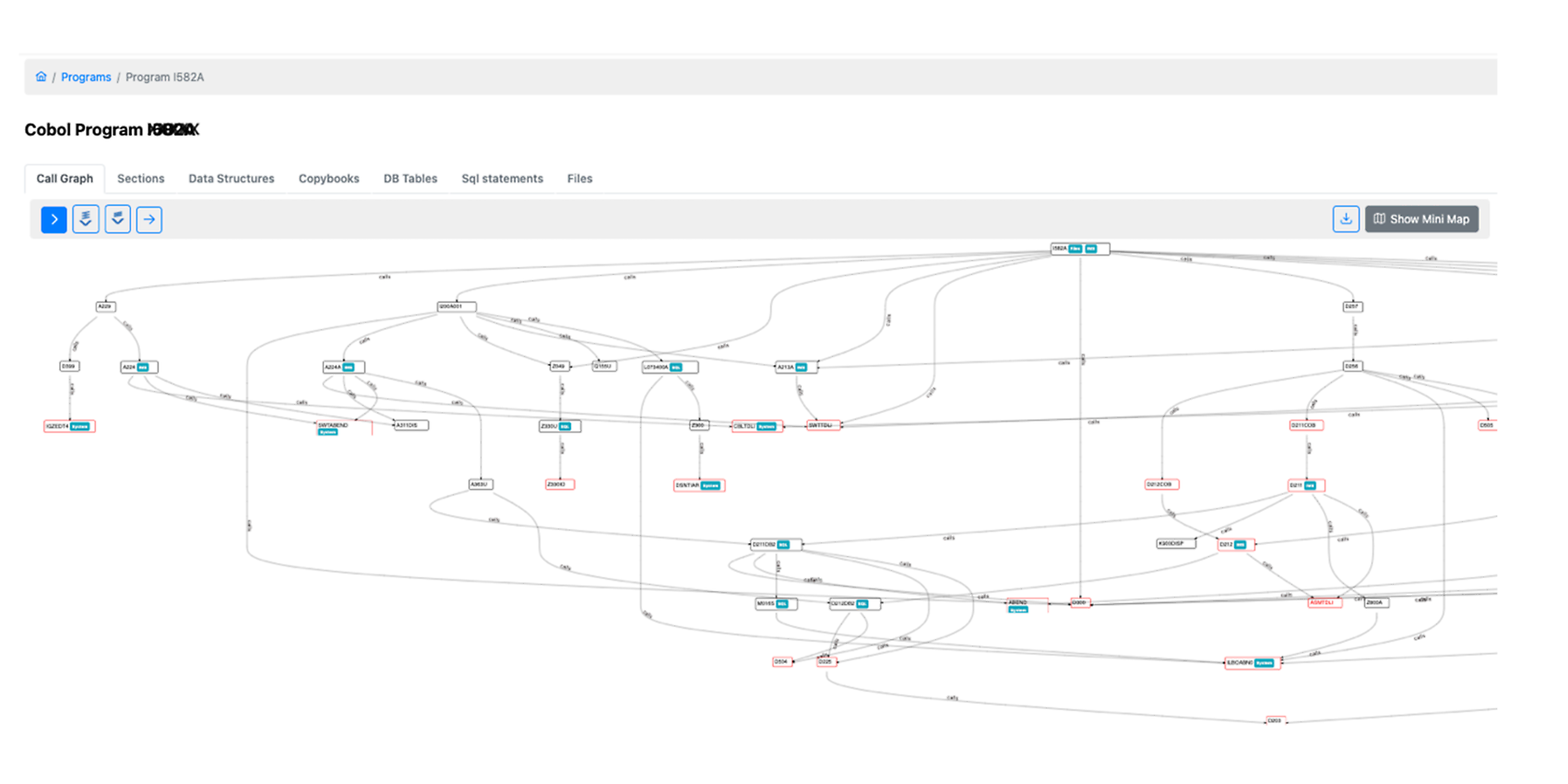
Programm-Detailseite in at|analyze
at|analyze enthält noch weitere Features. Dazu zählen:
Artefakt-Details
- Übersicht des Artefakt-Call-Graphens
- Gruppierung der Programm-Sections
- Gruppierung der Programm-Data-Structures
- Gruppierung der Programm-CopyBooks
- Gruppierung der angesprochenen Datenbanktabellen
- Gruppierung der aufgerufenen SQL-Querys
Reporting
- Inventory-Report: Übersicht, Statistiken und Diagramme der Analyse
- Missing-Objects-Report: Übersicht über alle gefundenen Programme ohne Source Code
- Migration-Report: Übersicht über den aktuellen Migration-Stand
- Call-Tree-Report: Übersicht über einen bestimmten Call-Tree eines Programms
Fazit
Mit at|analyze ist es möglich, anhand von verschiedenen Parsern, einer Graphdatenbank (Neo4J) und einem reichen Portfolio an Features ein Altsystem oder einen Legacy-Code genaustens zu analysieren. Bei über Jahrzehnten gewachsenen Cobol- und/oder Assembler-Software-Projekten ist eine Legacy-Code-Analyse unumgänglich.
Altsysteme bremsen den digitalen Wandel! Ihr seid auf der Suche nach der passenden Lösung? Dann werft einen Blick auf unsere Webseite und sprecht unsere Expertinnen und Experten der adesso Transformer GmbH an.
Weitere spannende Themen aus der adesso-Welt findet ihr in unseren bisher erschienenen Blog-Beiträgen.

Kategorie: |
|
Schlagwörter: |
Altsysteme Neo4j |

