
21. January 2021 By Libor Karger
Optimising banking processes – great potential for artificial intelligence
Clearstream Banking SA, a wholly-owned subsidiary of Deutsche Börse AG, has reached a settlement worth $152 million in a dispute with the US Office of Foreign Assets Control (OFAC). The dispute was centred around a violation of sanctions that had been imposed on Iran.
The row with the US authorities is costing Commerzbank dearly. Germany’s second largest financial institution must pay $1.45 billion to cast off accusations of sanctions violations and money laundering.
These are two examples that demonstrate just how important the area of surveillance, or in other words, the monitoring of processes for regulatory and compliance reasons, is for banks. That’s why a number of real-time checks – known as controls – are carried out when transactions are processed. All transactions are checked for fraud, sanctions or money laundering. A bank’s goal is to achieve the highest violation detection rates that it can.
Banks already use automated systems for these sorts of checks. However, they don’t achieve a one hundred percent detection rate. These types of systems automatically detect a certain percentage and send the remaining transactions on for manual processing. If you assume that large banks process something in the vicinity of hundreds of millions of transactions a day, and ideally 90 to 95 per cent of those can be processed automatically by existing systems, you get some idea of the tremendous amount of manual effort involved.
Project example: A system that checks transactions for sanctions
There are a huge number of ways in which artificial intelligence methods can be used to help out in this area. adesso has built a system for a large international bank that is able to reduce the number of transactions that need to be processed manually when checking for sanctions by up to 70 per cent. I’ll take a closer look at this system, its architecture and how artificial intelligence is deployed below.
System description: About the requirements of the subsystem
The subsystem responsible for checking sanctions needed to be highly flexible and variable from the outset. After all, a wide range of different bank transfer formats need to be covered at this point. The application should be able to adapt to special circumstances quickly. The range of formats is particularly wide in the case of bank transfers, as formal formats – such as SEPA (the Single Euro Payments Area, a format for cross-border EUR bank transfers) – as well as a large number of other semi-formal formats have to be factored in here. Entity recognition for addresses and names in free text, for instance, is very difficult to produce automatically through programming, as these are too complex. This is where natural language processing comes in handy as it is able to extract sentence components as entities from the context of the text. For this purpose, a specific model must be trained that is optimised for the circumstances in the referral texts and can recognise these entities.
Based on this, a set of rules is needed that can find the recognised entities in different sanction lists and produce few false positives. False positives in this context are matches – for example, company names without the context of the address.
At the same time, the recognition had to be traceable and reproducible so that the system could be checked by the auditor.
Architecture: About the structure of the system
The system is divided into several main components, which internally disaggregate following the onion architecture and communicate with the outside world via adapters.
The Spring Boot Framework with Java was chosen as the core technology because it is lightweight and flexible. The programming language Python is the de facto standard in the field of ML and, together with the spaCy framework, is responsible for natural language processing and entity recognition. spaCy is based on neural networks.
Three main components were created: import/export, search and AI/ML. These are each designed as a microservice. The reasons for this were the technology mix and the need for a high throughput, which is achieved through the redundant design of the components.
The diagram below provides a rough overview of how the components are arranged and communicate with the system context and the relationship between them.

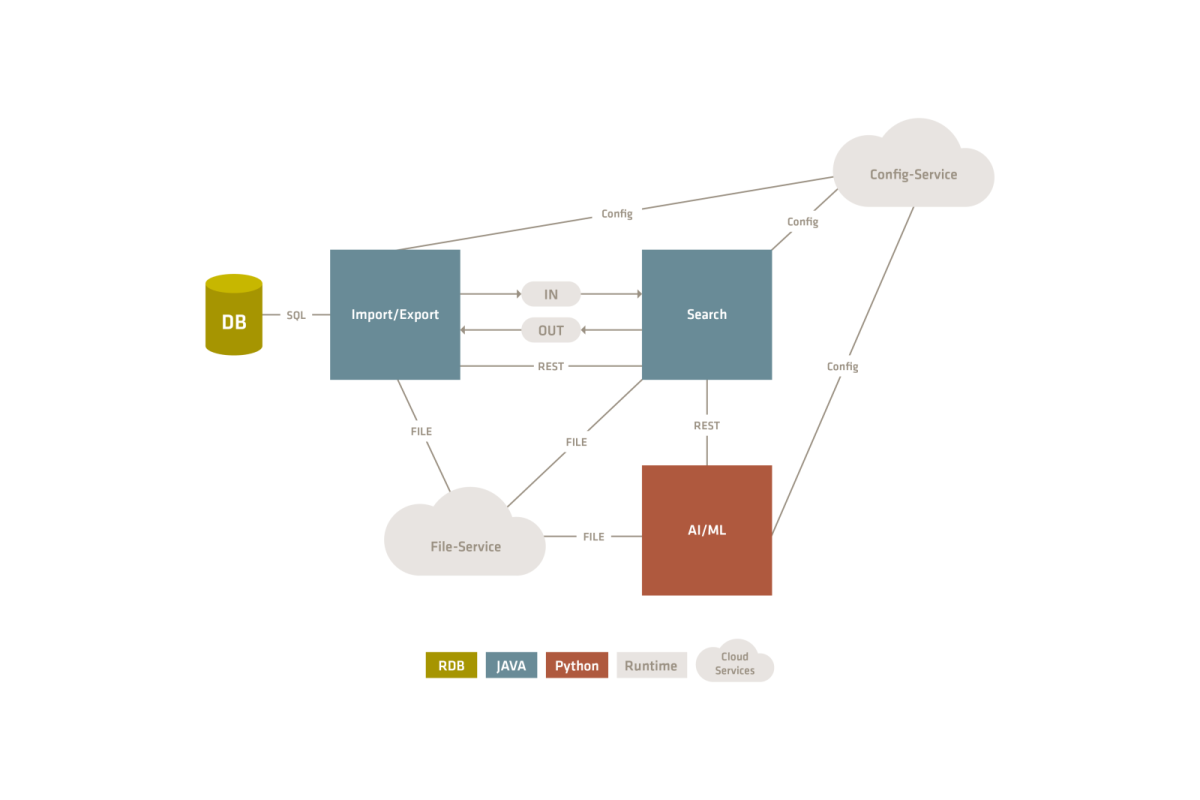

Communication between the components is synchronous via REST and asynchronous via messaging queues. Communication within the components is technology neutral and takes place using the JSON format.
ML methods
spaCy is an open-source library for advanced natural language processing in Python and is suitable for use in production. spaCy performs the tasks of entity extraction in this solution, using its Name Entity Recognition feature. Named entity extraction requires a specific neural network model to be trained. This model is often optimised to achieve even better results. For this purpose, spaCy provides some hyperparameters that influence how the neural network learns. The models are static and can be loaded. spaCy offers a variety of pre-trained models for download – however, they aren’t suitable for this task.
Therefore, special attention was paid to the source data used to train the model. Synthetic data isn’t exactly suitable here as there is a risk that the model is only as good as the algorithm used to generate the data. Anonymised or pseudonymised production data tends to be more suitable for building the models. Production data is always the first choice, as long as data protection allows it.
In order for the neural network to learn its own entities, the data must be annotated. This can be created with Doccano, for example. The text data and the metadata from the annotation are used in training the neural network.
The better model is obtained not by using a large amount of similar data, but by the data containing a large variety of texts. From the total data set, one quarter of the data is retained to test the model and three quarters of the data is retained to train the model.
The training is evaluated using the error gradient of the loss function, which determines the relationship between the recognised data and the expected results during the training of the neural network. Further optimisations are then identified based on this.
Conclusion
This solution illustrates the potential for optimisation that solutions supported by AI/ML for fraud prevention offer, as well as what difficulties this area faces and what solutions are already out there now.
Would you like to learn more about exciting topics from the world of adesso? Then check out our latest blog posts. Our latest AI report for banks and financial services providers is waiting for you on our AI page – check it out to discover everything you need to know about AI in the banking sector.

Category: |
|
Tags: |
Banks and financial services Artificial Intelligence (AI) |
